AIE Miami Day 2: Learning Agency: People, Companies, Agents
Day 2 at AIE Miami had a through-line I didn't fully see until the end of the day. It's about agency — but agency in three different senses, for three different populations, all happening at once.
People are learning agency over agents — how to delegate, how to review at a higher layer of abstraction, how to write in English well enough that an agent actually does the thing.
Companies are learning to grant agency to agents — agents as a new customer class with their own pricing, their own identity, their own onboarding surface.
Agents are learning agency themselves — memory, sub-agents, knowledge graphs, the professional-licensee upkeep loop. And we're the tenders.
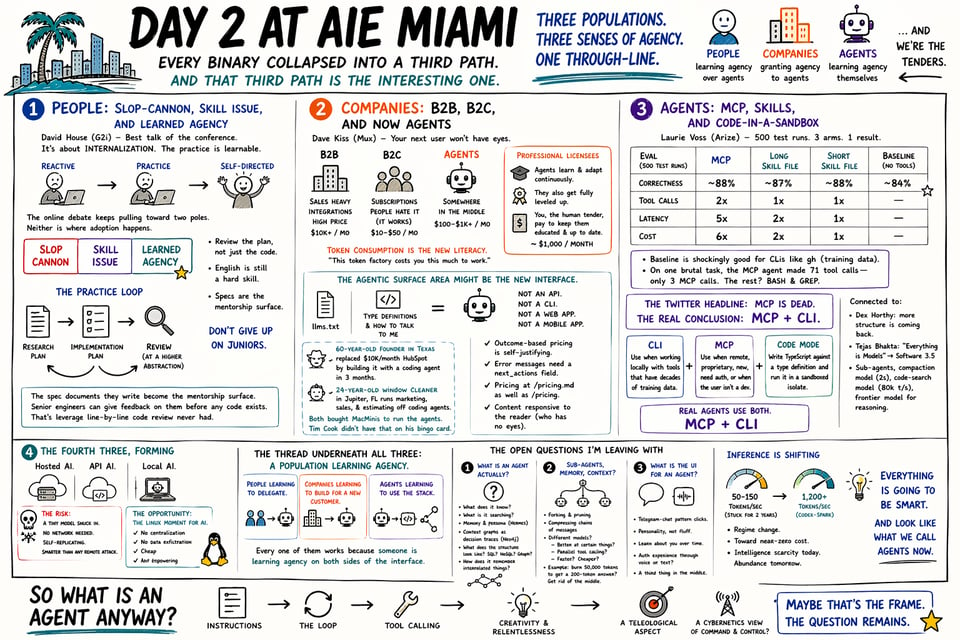
The shape of each one kept coming back to a rule of threes. Every binary the industry has been arguing about collapsed into a third path, and in every case the third path was the interesting one. Yesterday we saw that MCP-versus-skills debate start to crack. Today the same shape showed up everywhere. Three of those three-way frames hardened enough to name.
People: slop-cannon, skill issue, and learned agency
David House from G2i gave the best talk of the conference on this, drawn from five engineer case studies on a real project. He came from a mental-health counseling background before becoming an engineering manager, which shows — his frame is that successful agent adoption isn't about skill and it isn't about the framework. It's about internalization. Engineers start reactive, disempowered, reacting to output they don't trust, and they end self-directed. They learn agency.
The online debate keeps pulling toward two poles — slop cannon or skill issue. House's point is that neither pole is actually where adoption happens. The third thing is the practice, and it's learnable.
How do junior engineers live in this new world? You start by looking at prompts. If you look at most software development, there's always a research-plan loop in there. However it's structured — feature spec versus product spec, whatever — plus an implementation plan. It's a common pattern. The quality of those plans actually determines how well the thing does. So instead of just reviewing the code and magically saying the thing works, you need to review the plan.
That review process — instead of being code review by a senior engineer looking at a code PR — maybe is a prompt review. A spec review. You go and learn how to effectively communicate with your agent, because it's all about communication. English communication is still a hard skill, no matter if you're talking to a person or an agent.
House's closing line landed: don't give up on juniors. The spec documents they write become the mentorship surface. Senior engineers can give feedback on them before any code exists. That's leverage line-by-line code review never had.
Companies: B2B, B2C, and now agents
Dave Kiss from Mux gave a talk called Your next user won't have eyes that named the pattern I keep coming back to. We live in a world of B2B and B2C, but now there's a third type of software customer: agents. The SaaS-pocalypse represents the previous forces of how things worked. B2B had sales forces and salespeople and staff and integration costs, and then they came up with some ridiculous number to charge per month. Good business. That Salesforce tower is super tall. B2C has devolved into subscription, which people hate, but it's a good business.
Agents are somewhere in the middle. Not a $50 price point, not a $10,000 price point. Anthropic's Max plan is $200 a month. You pay per token; you can go up to a thousand a day. What does that look like?
The model I came up with is professional licensees — the teachers at a school who have a few days a month or quarter for continuous learning, or the doctor who goes back to conferences to keep certifications. The agents do the same thing. There's the part where they learn on their own and adapt, and there's the part where they get fully leveled up. You, as the human tender of the agents, pay someone a thousand bucks a month to keep your things educated and up to date.
At the very least, people understand token consumption. If you were to tell them this is a token factory and it costs you this much to work, that's something they can grasp.
Dave's whole talk is the product-side companion to this. GitHub commits per year are going vertical — not because humans got 10× more productive, because agents are the committers. Friction compounds at scale. Per-seat pricing is dead the second a "seat" is an agent. Your API access page can't say "contact sales" anymore; outcome-based pricing is self-justifying, flat-rate subscriptions are easy to cancel. Your error messages need a next_actions field. Your pricing should live at /pricing.md as well as /pricing. Your content should be responsive to the reader, and the reader no longer has eyes.
The echo from Rick Blalock at Agentuity was loud. A year ago he was selling a developer platform. Now he's explicit that the coding agent is a universal primitive — not just for developers. He told two stories that stuck with me. A 60-year-old manufacturing-company founder in Texas replaced a ten-thousand-dollar-a-month HubSpot subscription by spending three months having a coding agent build the replacement. A 24-year-old window cleaner in Jupiter, Florida runs his marketing, sales, and estimating off coding agents. Both of them bought MacMinis specifically to run the agents. Tim Cook didn't have that on his bingo card.
Our software needs to be agentic-ready, and in some ways the agentic surface area — whether it's just llms.txt, or "here's my TypeScript type definition, and this is how you talk to me" — might be the new interface. It's not an API. It's not a CLI. It's not a web app. It's not a mobile app. It's "here's how you can assemble your own library and figure out how to talk to me, even though the protocol is actually code."
So if this is now a fundamental building block of software, what does that mean for the way other software presents itself? You, as the human, need to learn what the latent space is — the latent space of interaction and requests. That's the new literacy.
Agents: MCP, skills, and code-in-a-sandbox
Laurie Voss from Arize ran the evaluation the internet has been arguing about for months. Five hundred test runs, three arms — MCP, a long skill file, a short skill file — plus a baseline with no tool context at all. The whole Twitter debate between MCP stans and skills evangelists, resolved with data.
His result: correctness is a wash. All arms land in the high 80s. But MCP uses roughly twice the tool calls, five times the latency, and six times the cost on complex tasks. The short opinionated skill file beats everything on speed. Baseline is shockingly good for a famous CLI like gh because the training data is doing most of the work. And on one particularly brutal task, the MCP agent made 71 tool calls — only three of which were MCP calls; the rest were the agent using bash and grep anyway, despite being told not to.
The Twitter-worthy headline is that MCP is dead. But the real conclusion is more interesting, and Laurie landed it cleanly: it's not MCP versus CLI. It's MCP plus CLI. Real agents use both. Claude Code uses both. Cursor uses both. CLI when you're working locally with a tool that has decades of training data behind it. MCP when the tool is remote, proprietary, new, when you need auth management, when the user isn't a developer.
The third thing underneath both of those is code mode — letting the agent write TypeScript against a type definition and run it in a sandboxed isolate. That's really Monday's story carried into Tuesday. Kent Dodds' Kody, Rita Kozlov's server-side code execution, Ben Davis's Gen-3 SDKs — those are the real architectural answer, and Laurie's eval confirms it by negative proof. When the agent can write code, it does; when you force it not to, it smuggles bash in anyway.
This connects to Dex Horthy from Monday. Giving the pieces to the models and letting them go wild is too far. Giving them more structure is coming back. Code inside a sandbox is that more-structure. And Tejas Bhakta's "everything is models" talk added the architectural how: specialized sub-agents, a compaction model running at 2 seconds, a code-search model at 80k tokens per second, a frontier model doing only the reasoning. Software 3.5, he called it.
The thread underneath all three
All three threes are the same shape — a population learning agency. People learning to delegate. Companies learning to build for a new customer. Agents learning to use the stack.
That's what made Tuesday feel different from Monday. Monday was patterns breaking. Tuesday was three new patterns hardening at the same time, and every one of them named a third path where there had only been a binary. Every one of them works because someone is learning agency on both sides of the interface.
The fourth three, forming
One more thing caught my attention that I didn't see on stage but had in the hallway. Running local models — so-called "open source," but fundamentally what I mean is models that run at the cost of electricity, or run without a network.
I had a hallway conversation with someone in cybersecurity. One of the exploits they're seeing is a tiny model snuck in through a phishing attack and running locally inside the target's environment, doing all the hacking without needing to talk to a command-and-control server. The usual detection mechanism — anomalous network traffic while the attacker probes for holes — doesn't work. You deliver the payload and the machine itself becomes a self-replicating virus. Much, much smarter than anything command-and-controlled remotely can be.
Flip it positive: so many of our problems with how AI gets deployed would go away if we were just running it on the GPU you have in your laptop. No centralization. No data exfiltration. Cheap. The Linux moment for AI would look like that.
I don't think this three is named yet. Hosted AI, API AI, local AI. Watch this space.
The open questions I'm leaving the conference with
What is an agent actually? What does it know? What is it searching? I liked the Hermes project a lot because of the way it thinks about memory and the way it models your persona, but there's a deeper knowledge-graph thing underneath — Nyah Macklin's Neo4j talk got at part of it with context graphs as decision traces, though she was talking more about auditability than memory. What does the structure actually look like? SQL database? NoSQL? Graph? Is there a way an agent can remember interrelated things?
Sub-agents — the equivalent of forking and pruning. I think there's a whole unexplored area around taking these chains of messages and compressing them. Are sub-agents different models, better at certain things, better at parallel tool-calling? Are they faster? Cheaper? The obvious case: "I have this thing that burns 50,000 tokens to reach a 200-token answer, so I can just get rid of the stuff in the middle." What are sub-agents, what is memory, what is context — still ripe for deeper thought.
And then: what is the user interface for an agent? The Telegram-chat pattern clicks in people's minds. There's a personality. It's not flirting with you. It's not bullshitting you. It's not hanging out. Because text has become our dominant way of socially interacting, putting the agent on the other side of that made it real. It's a very skill-based thing — and I don't know if skills is the right term there either. I do think there's a third thing in the middle where you get some of the MCP authentication experience through a voice- or text-chat interface where you have a back-and-forth and it learns about you. Another three forming.
Inference is shifting too. Sarah Chieng's Cerebras talk named it — speed has been stuck at 50–150 tokens per second for two years while capability grew. Codex-Spark at 1,200 tokens per second is a regime change. I didn't use it yet, but the direction is inference trending toward zero cost. Right now we're super, super starved for it. Who knew how much compute we actually needed? Who knew how many questions we needed to ask? We're in an intelligence scarcity, as it turns out. Once everything is smart, then that's where we're going. Everything is going to be smart, and it's going to look like what we call agents now.
So what is an agent anyway? There's a context, there's the loop, there's the tool calling, and there's the ability to solve problems in creative ways — the relentlessness. There's the instruction. Maybe that's what it is: instructions, a teleological aspect. Maybe there's a cybernetics view of command and control underneath it. Maybe that's the framing.
What is an agent — it's still the question.